

AI는 이제 단일 모델의 한계를 넘어서, 여러 모델을 결합하는 앙상블(Ensemble) 전략으로 돌아왔습니다.
지난 실험에서는 Random Forest와 LSTM 모델을 적용했지만, 실제 데이터 예측에서는 아쉬운 결과를 보였죠.
이번엔 AI 모델들이 힘을 합쳤습니다. 어떤 결과가 나왔을까요? 🎯
🤖 “AI, 협업을 시작하다”
지금까지의 과정은 다음과 같았습니다:
- 과거 로또 번호 데이터를 수집하고
- 데이터 전처리를 통해 학습에 적합한 형식으로 가공한 뒤
- 머신러닝(Random Forest)과 딥러닝(LSTM) 모델로 분석을 시도했습니다.
그러나 결과적으로, 예측의 정밀도는 기대에 미치지 못했습니다.
그래서 이번에는 여러 모델의 결과를 조합해 성능을 높이는 앙상블 전략을 도입했습니다.
앙상블이란 간단히 말해,
“서로 다른 AI 모델들이 예측한 결과를 종합해 최종 판단을 내리는 방법”
이번에는 Random Forest, LSTM, XGBoost 세 모델이 함께 예측에 참여했습니다
📊 “예측 결과는?”
앙상블을 통해 생성된 예측 번호는 다음과 같습니다:
- 예측 번호 (1001회)
[Random Forest 예측] : [2, 8, 19, 22, 32, 42]
[XGBoost 예측] : [2, 8, 19, 22, 32, 42]
[LSTM 예측] : [2, 8, 19, 22, 32, 42]
그리고 실제 로또 번호는?
- 실제 번호 (1001회) → [6, 10, 12, 14, 20, 42]
믿기지 않겠지만…
이번에도 예측 번호는 1개가 맞았습니다! 😭


모델 학습 방향을 바꾸어야 할듯 합니다.
모델 간 예측 다양성 확보 및 앙상블 효과 향상이 가능한 방법으로 변화를 시켜보겠습니다.


"XGBoost 예측 모델"은 [6, 42] 2개 맞추었네요 😳


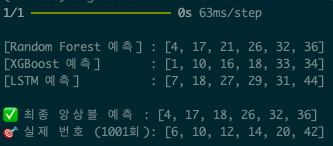

여러번 시도를 해도 예측번호 2개 이상은 쉽지 않네요. 😰
💡 “분석 전략, 전환이 필요할 때”
이번 실험에서 얻은 중요한 통찰은 다음과 같습니다:
- 머신러닝 모델은 과거 패턴 분석에는 효과적이지만,
- 완전한 무작위성에 가까운 데이터에서는 예측 다양성 부족으로 한계가 발생할 수 있습니다.
- 특히 앙상블 전략도, 각 모델이 유사한 결과를 낼 경우 효과가 제한적입니다.
이를 보완하기 위해, 다음 실험에서는 모델 간 예측 다양성을 확보하고
더 폭넓은 조합을 탐색할 수 있는 방법으로 전환합니다.
🚀 “다음 전략: 강화학습”
다음 실험에 도입할 강화학습(Reinforcement Learning)은 기존 방법과는 다릅니다.
- 강화학습은 다양한 숫자 조합을 시도하며,
- 성과(보상)를 기준으로 더 나은 전략을 스스로 학습합니다.
즉,
“데이터 기반 패턴이 아닌, 전략 기반 탐색이 가능해진다”
는 것이 핵심입니다.
이 방식은 무작위 데이터 환경에서도 새로운 가능성을 제시할 수 있습니다.
🔧 “실험 환경 업그레이드: GPU 활용”
강화학습은 계산량이 많기 때문에, GPU가 필수입니다.
이번 실험에서는 GPU 환경을 활용해 학습 속도와 성능을 높일 계획입니다.
AI가 다양한 조합을 어떻게 탐색하고, 어떤 방식으로 학습해 나가는지 직접 확인해보세요!
📖 용어 정리
- 앙상블(Ensemble) → 여러 AI 모델을 결합해 최종 예측 성능을 높이는 방법
- XGBoost → 부스팅 기반 머신러닝 알고리즘, 성능과 속도가 빠름
- 강화학습(Reinforcement Learning) → 시도와 보상을 통해 AI가 스스로 최적 전략을 학습하는 방식
- GPU → 병렬 연산에 강한 그래픽 카드, 딥러닝·강화학습에 필수
🔮 앞으로의 실험 방향은?
강화학습 모델을 적용해 AI가 스스로 번호 조합을 탐색하는 방식으로 접근할 예정입니다.
GPU 환경에서의 학습으로 기존보다 더 다양한 조합과 전략이 시도될 것이며, 무작위성에 가까운 데이터에서 AI가 어떤 방식으로 대응해 나가는지 그 가능성을 하나씩 검토해볼 계획입니다.